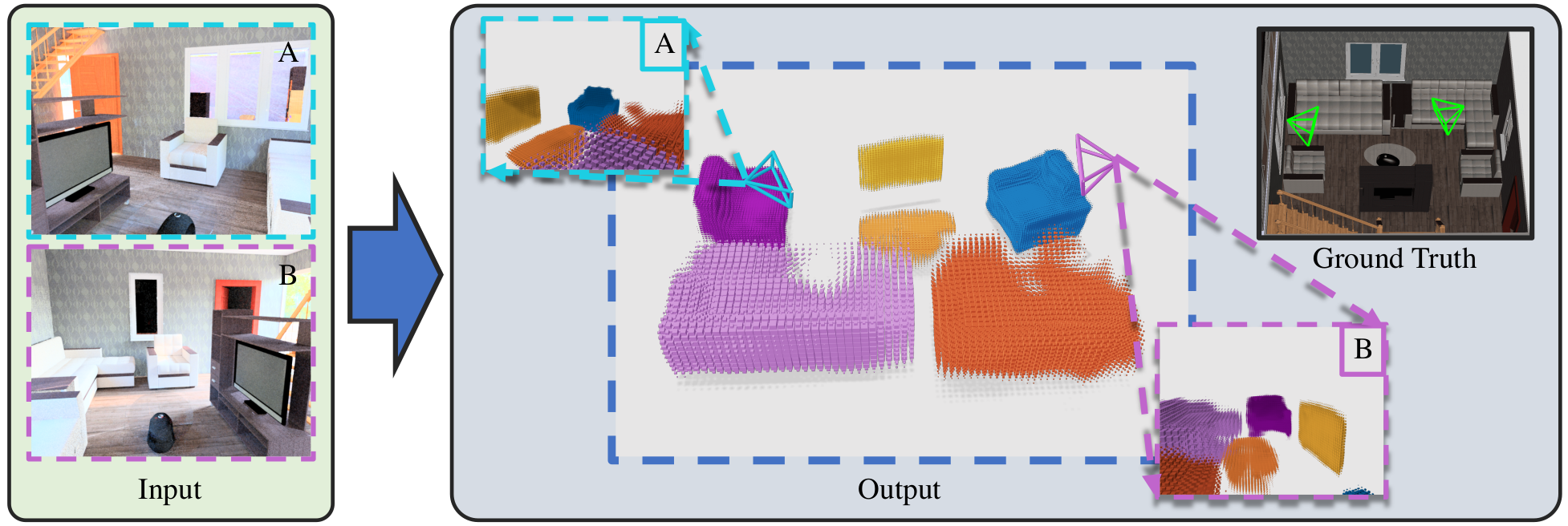
Given two views from unknown cameras, we aim
to extract a coherent 3D space in terms of
a set of volumetric objects placed in the scene.
We represent the scene with a factored representation that splits the scene
into per-object voxel grids with a scale and pose.
This paper studies the problem of 3D volumetric reconstruction from two views of a scene with an unknown camera. While seemingly easy for humans, this problem poses many challenges for computers
since it requires simultaneously reconstructing objects in the two views
while also figuring out their relationship. We propose a new approach
that estimates reconstructions, distributions over the camera/object and
camera/camera transformations, as well as an inter-view object affinity
matrix. This information is then jointly reasoned over to produce the
most likely explanation of the scene. We train and test our approach on
a dataset of indoor scenes, and rigorously evaluate the merits of our joint
reasoning approach. Our experiments show that it is able to recover reasonable scenes from sparse views, while the problem is still challenging.
Interactive Results
View A
View B
Associative3D
Ground Truth
Acknowledgements
Toyota Research Institute (“TRI”) provided funds to assist the authors with their research but this article solely reflects the opinions and conclusions of its authors and not TRI or any other Toyota entity.