| Category |
Links |
Details |
| Video Clips |
pos_clips.tar.gz |
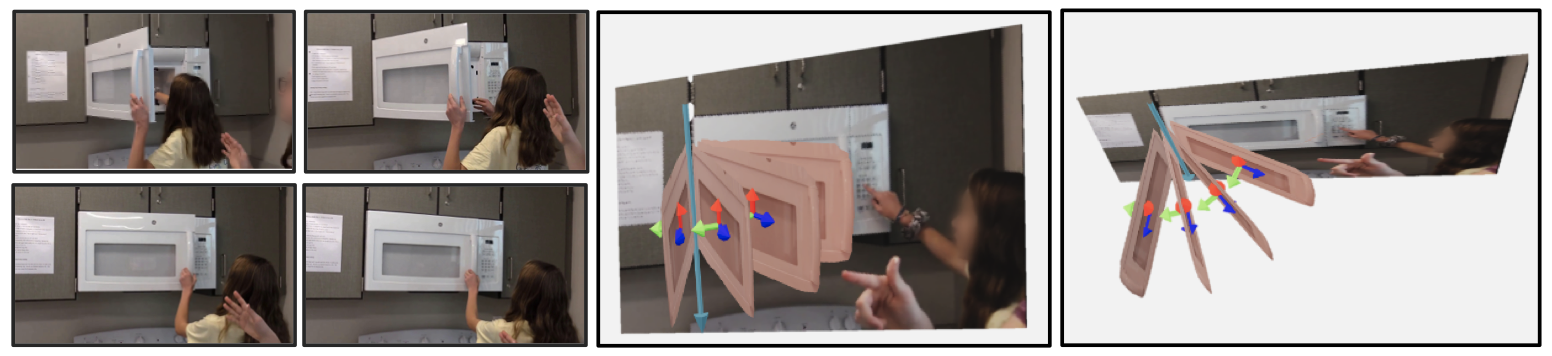
Articulation video clips. Each clip lasts 3 seconds. |
| Negative Clips |
neg_clips.tar.gz |
For each positive video clip, we try to sample a negative clip (no articulation) in the same scene with a hand motion. This is used for the recogition benchmark. |
| Frames |
articulation_frames_v1.tar.gz |
Key frames pre-extracted for the dataset. We extract 9 key frames for each video clip, which has 90 frames (fps=30). |
| Annotations |
articulation_annotations_v1.tar.gz |
Articulation annotations. Surface normals are only available in the test split. We have preprocessed annotations to COCO format. |