
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
The input is a single image and the corresponding action (e.g, ``hold''). The output is a heatmap which highlights regions one can interact. We aim to enhance the generalization capability of affordance grounding to in-the-wild objects that are unseen during training, by developing a new approach, AffordanceLLM, that takes the advantage of the rich knowledge from large-scale vision language models beyond the supervision from the training images. |
Benchmark |
| Category | Links | Details |
|---|---|---|
| Hard split | agd20k_hard_split.tar.gz | Our hard split of AGD20K. The original images can be downloaded from AGD20K. |
Approach |
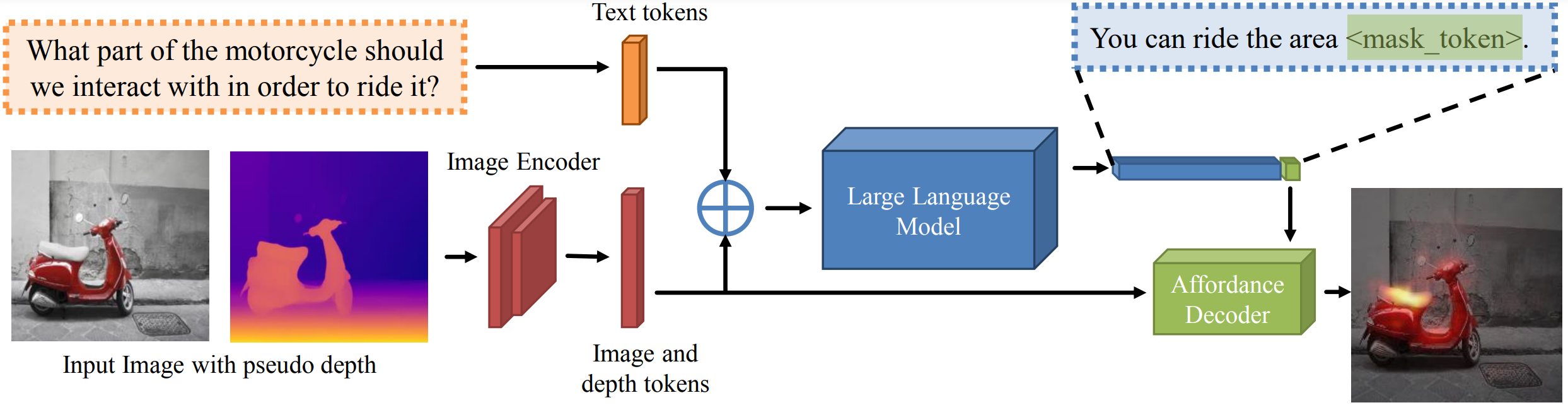 |
The input is a single image and the corresponding action (e.g, ``hold''). The output is a heatmap which highlights regions one can interact. We aim to enhance the generalization capability of affordance grounding to in-the-wild objects that are unseen during training, by developing a new approach, AffordanceLLM, that takes the advantage of the rich knowledge from large-scale vision language models beyond the supervision from the training images. |
Results |

Generalization Results |

AcknowledgementsThis webpage template was borrowed from Nilesh Kulkarni, which originally come from some colorful folks. Thanks Wonjun for sharing the implementation of AffordanceLLM. |