| Category |
Links |
Details |
| Images |
images.tar.gz |
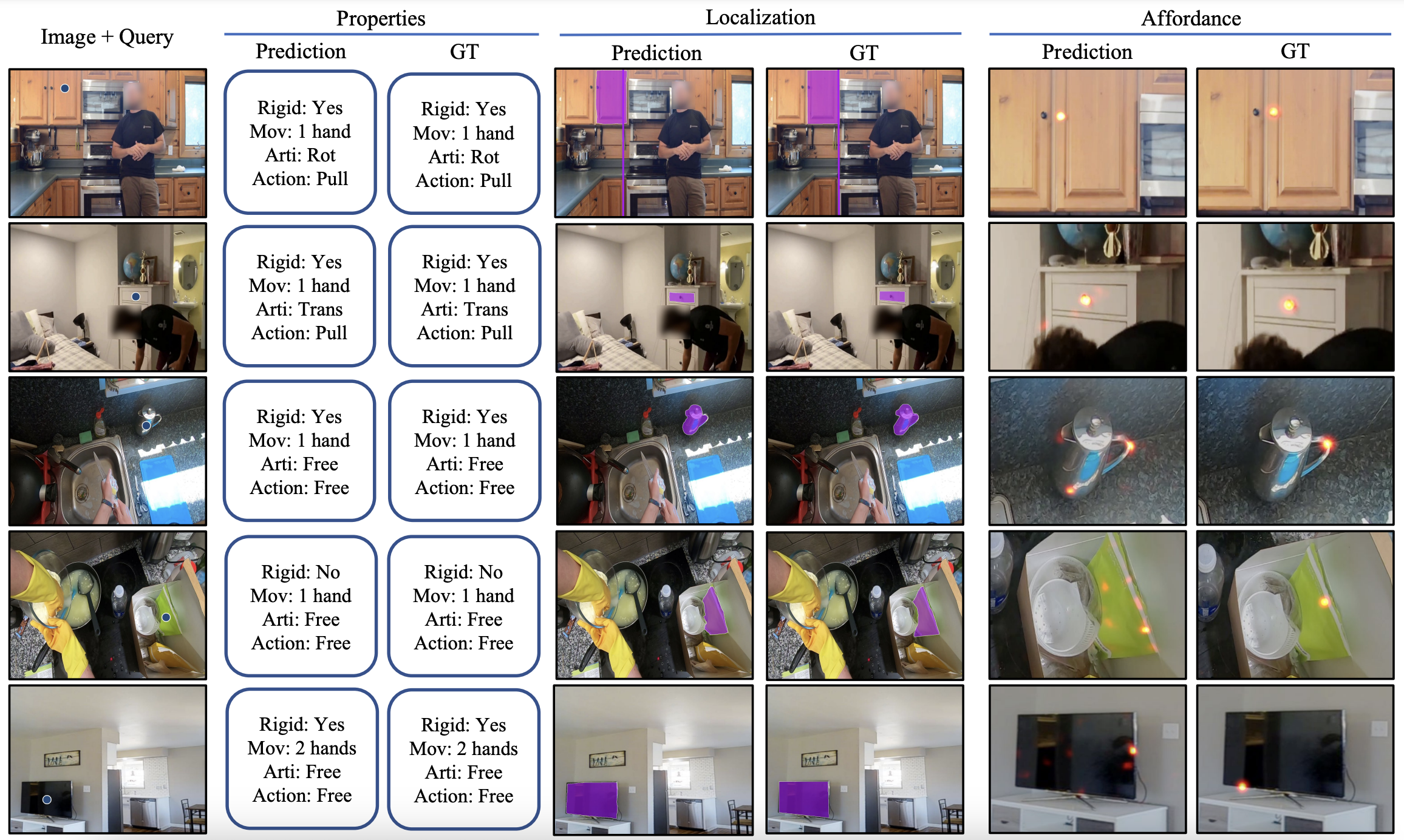
All images from Articulation, Epickitchen and Omnidata. The usage of Epickitchen and Omnidata are subject to their original license (Epickitchen and Omnidata). |
| Annotations |
3doi_v1.tar.gz |
Annotations for train, val and test split. The annotations of each split is stored in the pth file. Please check out our code about loading the data. |
| Omnidata Ground Truth |
omnidata_filtered.tar.gz |
You can download full ground truth from Omnidata. However, we filter ground truth for images included in our data, and provide a separate download link. |